Maelstrom Research and its partners have developed multiple open-source tools for data collection, management, harmonization, co-analysis, and dissemination in epidemiological research. Rmonize and its related R packages provide users with functions to support data harmonization in R environments, while the OBiBa software suite includes a series of integrated, modular applications to support the entire data management lifecycle. All tools are freely available under a GPL-3 licence.
For more information, contact us.

Rmonize is an R package that supports structured and well documented processing of data from individual studies into a common harmonized format. It provides functions to prepare and validate the required inputs (see figure below) and produce harmonized datasets and documentation based on the user-specified list of variables to generate (DataSchema) and elements and algorithms for data processing (Data Processing Elements). Rmonize also includes functions to identify potential processing issues and produce descriptive summaries and visual reports of harmonized variables. As such, Rmonize provides a streamlined reusable pipeline that helps users to improve the efficiency, consistency, and transparency of their harmonization initiatives.
Rmonize is easily used with other Maelstrom Research R packages for data processing and Opal software for secure data management.
Rmonize processing pipeline:
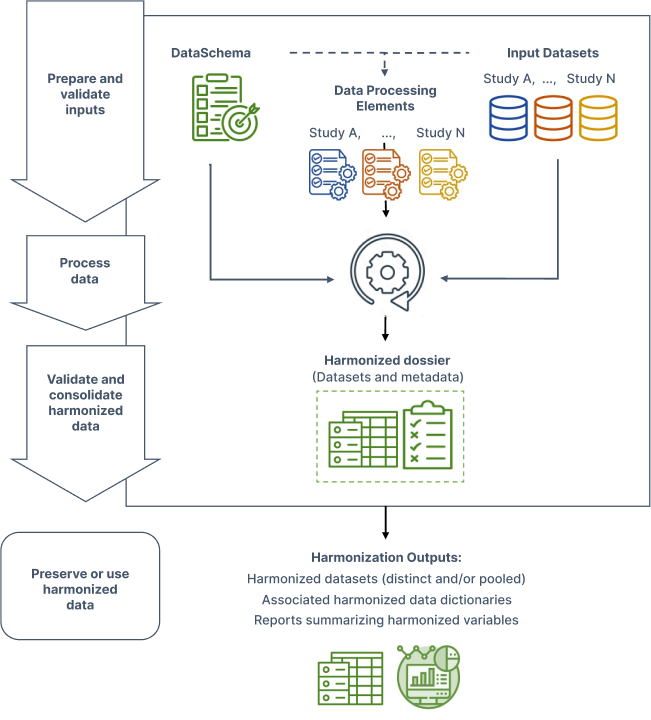
Rmonize's main features
- Open-source R package, with access to the extensive resources of statistical language and RStudio environments.
- Published on CRAN with source code and updates available on GitHub.
- Optimized for use in RStudio server environments and compatible with 'tidyverse' syntax.
- Use of spreadsheet templates to specify the DataSchema and Data Processing Elements reduces the amount of coding needed in R and simplifies creation of user-friendly documentation.

Mica is a software application used to create online portals for individual epidemiological studies or multi-study networks. It helps investigators and data custodians efficiently disseminate information about their studies and networks. As such, Mica allows annotation, organization, and dissemination of study and variable metadata. A web-based search interface then allows users to browse and query this metadata, thereby helping them identify studies and data items of interest to answer their research questions. Mica also includes other useful communication and dissemination features.
When used with Opal software, Mica allows authenticated users to securely retrieve descriptive statistics and perform distributed queries on geographically dispersed servers hosting study data.
Mica's main features
- A client-server architecture with multiple software clients available
- Support for longitudinal study designs, allowing documentation of various study populations and data collection events
- A powerful search engine to browse, query, and compare study and variable metadata
- Data access management tools, including customizable online data request forms

Opal is a software application used to manage, harmonize, and integrate epidemiological study data. As a central study data repository, Opal allows users to import, validate, derive, analyze, and export data. Opal provides a uniform interface capable of integrating data collected from multiple sources for a single study, and enables the derivation of common-format (i.e., harmonized) data across multiple studies. The Opal application also provides a state-of-the-art software infrastructure for data encryption, participant-identifier management (with import and export functions), and user authentication/authorization.
When connected to a central Mica web interface, users can seamlessly and securely search distributed datasets across several geographically dispersed Opal servers.
Opal’s main features
- Store data on an unlimited number of variables using customizable data dictionaries
- Support various data formats including CSV, SPSS, and XML
- User-friendly interfaces to develop and implement data processing algorithms and document decision making when harmonizing data across studies
- Comprehensive JavaScript library of functions commonly used to derive new variables
- Descriptive statistics computation with graphical display (e.g., bar charts, scatter plots)
- Integration of the software with R to perform complex statistical analyses and generate reports

The D2K (Data to Knowledge) Research Group has developed DataSHIELD, an open-source solution for co-analyzing sensitive research data. DataSHIELD is an interface module between the Opal software application and the R statistical environment that enables the remote and non-disclosive analysis of study data. Under DataSHIELD, statistical analysis requests are sent from a central analysis machine to several data-holding Opal servers storing harmonized data. These datasets are analyzed simultaneously but in parallel, linked by non-disclosive summary statistics. With this approach, individual participant data from contributing studies are held securely on geographically dispersed local servers. Individual-level data thereby stay at source, within the governance structure and control of the originating study/institution. In summary, the analysis is taken to the data—not the data to the analysis.
Learn more about DataSHIELD here.